Phonemes and their Role in Text to Speech Pronunciation

Have you ever noticed how different the word 'bat' sounds compared to the word 'cat' ? Or how the word 'age' sounds different from the word 'cage' ? These differences in sound are the result of unique combination of phonemes that make up each word.
A phoneme is the smallest unit of sound that serves to distinguish one word or utterance from another in a language or dialect, such as the 'b' in bat and 'c' in cat, leading to differences in meaning. By itself, a phoneme has no meaning, but by combining phonemes, words can be created. You can segment or break apart any word to recognize the different phonemes used in that word. For example, the word 'sun' has three sounds or phoneme: /s/ /u/ /n/.
Phonemes are also language-specific. Some letters can have the same sound (like 'c' and 'k' in 'car' and 'key') and some others, distinct sounds. In English language, there are a total of 44 phonemes, which include 18 consonants, long vowels, short vowels, six digraphs, 12 monophthongs, and eight diphthongs. A digraph is when two letters make a single phoneme. Examples of diagraphs include 'oa,' which is a vowel digraph, and 'th,' which is a consonant digraph. Let's consider the word 'boat.' Boat comprises three phonemes: /b//oa//t/, out of which the middle /oa/ is a digraph.
Some words also contain what is known as consonant clusters two consonants or more placed together such as 'tr' in 'trap' and 'mp' in 'bump.' While both words contain four phonemes, you can still hear the two separate consonant cluster sounds.
Monothongs, on the other hand, are pure vowel sounds that are spoken with one tone and one mouth shape. And diphthongs are sounds that are created with two vowel sounds. They are also known as gliding vowels, as one vowel sound glides into another.

Table of Contents
Types of Phoneme

Phonemes are divided into two categories: phones and allophones. Phones are the pure sound you make when pronouncing a word. For example, the letter 'p' in 'English language can be either pronounced as a voiceless bilabial stop [p] like in the word 'pat' or a voiceless labiodental fricative [f] as in the word 'photo.' These two sounds are considered to be two different phones of the /p/ phoneme. Allophones, on the other hand, are different versions of a phoneme that donot change the meaning of a word. Allophones function as a single sound. For example, the English phoneme /t/ can be pronounced as a voiceless alveolar stop [t] as in the word 'tap' or a voiceless dental stop [t̪] like in the word 'thin.' These two sounds are not distinctive in English and do not change the meaning of a word. In simple words, a phoneme is a set of allophones. Allophones are sounds, and a phoneme is a set of such distinct sounds.
Why are Phonemes Used?
Without phonemes, it would be difficult for one to understand what is being said. Phonemes form the foundation of reading, writing, and speaking. Given that there are an estimated one million words in English, learning to read and spell every word by sight is a complex and strenuous task. This is where linking the written letter (grapheme) to their speech sound (phoneme) and recognizing how these combine to make words can help.
In other words, a phoneme plays a significant role in helping distinguish different letter combinations, which allows us to sound out words and build our vocabulary. Phonemes enable readers to learn to pronounce different words correctly and comprehend their meanings. Good command over phonemes helps individuals get rid of confusion when encountering unfamiliar words. It's also useful when learning foreign languages.
Phonemes in Text to Speech
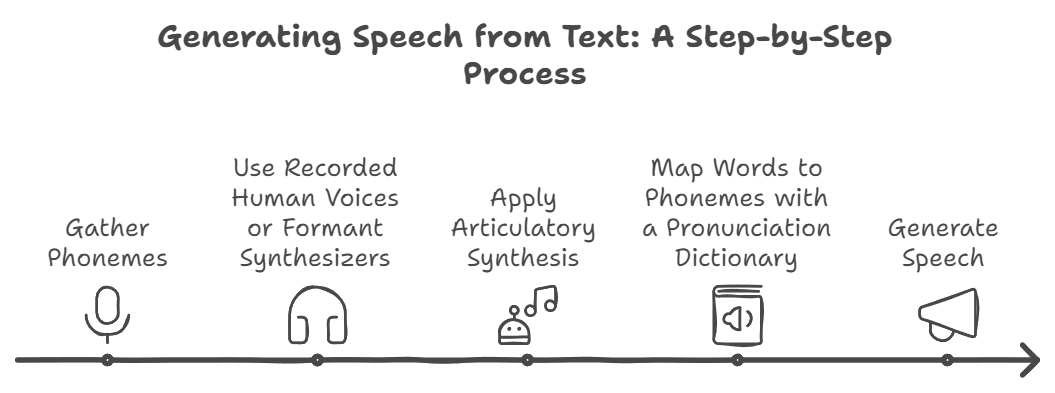
Phonemes also play an important role in natural sounding speech synthesis. Text to speech software usually rely on a phonetic system to read out words in a simulated voice. These systems essentially sound out each letter or common letters grouping the same way regardless of the meaning of the entire sentence or paragraph, often leading to the mangling of words pronounced differently based on tense (like read) or without regard for their verbal form.
But where do we get access to the basic phonemes that the speech synthesis system can rely on to read text out loud?
There are multiple approaches. Firstly, speech synthesizers that use recorded human voices have to be preloaded with recordings of human sound that they can rearrange in different ways to create entirely new words and sentences. A second approach is using formant speech synthesizers to generate phonemes by producing basic sound frequencies. Formant speech synthesizers can say anything, even words that don’t exist or foreign words they’ve never heard off. The synthesized speech output is created using additive synthesis and physical modeling synthesis. And, the final method is to use articulatory synthesis to make the computer mimic the mechanism of the human voice.
Most TTS systems today use a set of rules, known as a pronunciation dictionary, to map written words to their corresponding phonemes. This allows the text to speech software to pronounce words correctly and produce natural-sounding speech.
International Phonetic Alphabets (IPA) and their role in Speech Synthesis

International Phonetic Alphabets (IPA) are the world's most commonly used orthographic representation of words. It's a chart of alphabets and their corresponding individual sounds used by linguists to accurately represent the variety of sounds in human speech. The IPA helps people who speak different languages transcribe phonemes to understand each other. Using the IPA chart, a person speaking English can communicate easily with a native Spanish speaker. It is also used in music and speech therapy.
The IPA chart is based on the Latin alphabet to correspond to an international standard that represents the sounds of all 78 languages that use phonemic scripts. The symbols are grouped based on their features or the parts of the mouth used to pronounce them. IPA serves as an excellent means to represent sounds in writing.
In text to speech, the IPA chart can be used to provide a more accurate representation of the pronunciation of words, especially for languages with complex sound systems or for speakers with regional accents.
Using IPA and Phonemes in Murf
Murf text to speech platform uses three basic approaches to determine the correct pronunciation of a word based on its spelling: a dictionary-based approach, a rule-based approach, and using the IPA chart.
In the dictoinary based approach, a large dictionary containing all the words of a language and their correct pronunciations is stored in the TTS program. Determining the correct pronunciation of each word is a matter of simply looking up each word in the dictionary and replacing the spelling with the pronunciation specified in the dictionary. In the rule-based approach, pronunciation rules are applied to words to determine their pronunciations based on their spellings. This is similar to the 'sounding out,' or synthetic phonics approach to learning reading.
Murf also offers what is known as smart suggestions, which present a range of IPAs and alternative spelling for commonly used words. To access this feature, a user can simply double-click on a word that requires correction in pronunciation and choose the right IPA or alternative spelling from the list offered.


That said, Murf also accepts custom IPA and alternative spellings. Murf suggests using third-party websites like Dictionary, Tophonetics, Wiktionary, Easypronunciation, and other websites on Google to acquire the right IPA for pronunciations. These custom IPAs can be added to the list of suggested pronunciations under the 'custom' tab by clicking on the 'Add Pronunciation' button and accessed anytime in the future.

As text to speech technology continues to evolve, the accurate representation of phonemes will be essential for achieving high-quality and natural-sounding pronunciations.
Murf Customizations to Change your Phoneme Game
Murf's unique customization features has long been at the core of its ability to produce natural, human-like speech by focusing on the smallest units of sound. With the introduction of Variability, Murf takes this to the next level, enabling users to generate multiple voiceover versions of any line with just one click. This allows for nuanced delivery choices, making it easier to find the perfect tonal and emotional fit for various contexts like corporate videos, e-learning, or creative projects.
Complementing this is the new Word-level Emphasis feature, which enhances control over speech delivery at the granular level. While Variability allows users to select the best overall line delivery, Word-level Emphasis offers the ability to adjust the intensity and inflection of individual words within that line. Whether the goal is to emphasize the urgency of a particular safety instruction or to underscore irony in a narrative, this feature ensures that key words are delivered with the exact nuance the creator desires. Together, these tools significantly enhance Murf’s phoneme-based voice synthesis, offering unprecedented customization in voiceovers.
In conclusion
Oddly emphasized syllables and mispronounced words are often the most common flaws in text to speech systems; they mess up the illusion of a human behind the otherwise life-like synthetic speech. Murf's text to speech technology overcomes these quirks by combining a voice model that looks for context to determine how to say a word in tandem with a tool for teaching it proper pronunciation, should contextual clues fail.

FAQs
Why are phonemes important in text to speech?
Phonemes enable text to speech systems to arrive at the accurate pronunciation of words.
Why do we need phonemes?
Phonemes form the basics of reading, writing, and speaking. Linking a written letter (grapheme) to their sound (phoneme) helps in distinguishing different letter combinations, which allows us to sound out words and build our vocabulary.
How do I get phonemic transcription?
Phonemic transcription is the visual representation of speech sounds (or phones) in the form of symbols. The IPA chart is the most commonly used tool for phonemic transcription.


