How Does Conversational AI Work?
How does modern conversational AI systems work, this includes input processing, orchestration layers, RAG knowledge retrieval, workflows, tools, and monitoring that enable AI to maintain context, answer questions accurately, and perform real-world tasks.
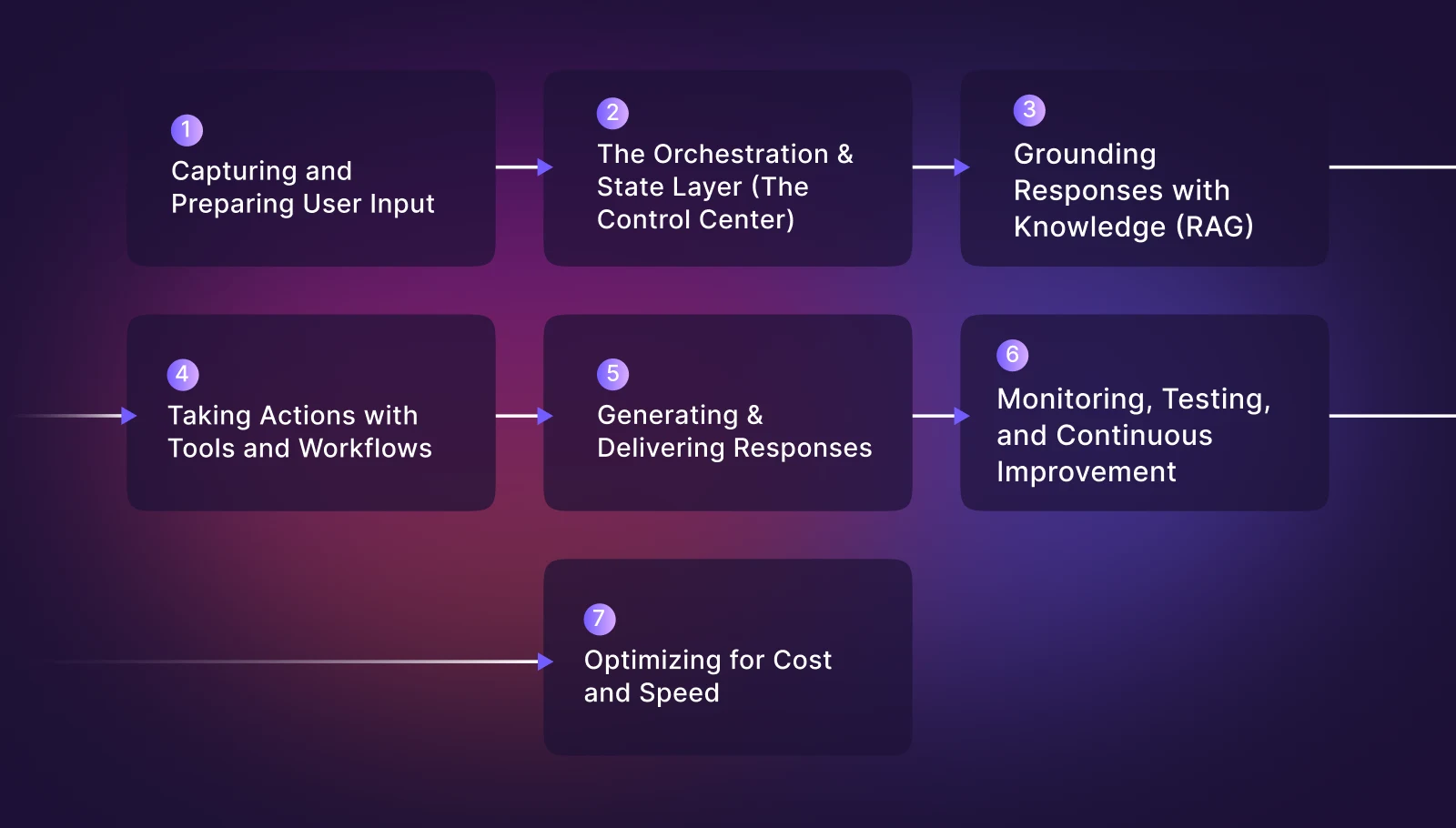
Modern conversational AI is a stateful, orchestrated system designed to understand users, maintain context, provide accurate answers, and even perform real-world actions like booking appointments or updating records.
At the core of the system is a large language model (LLM), supported by layers that manage conversation state, orchestrate workflows, retrieve knowledge, and connect to external tools. Together, these layers work like a team of specialists and form the components of conversational AI one listens carefully (speech recognition), another remembers important details (orchestration layer), the third finds accurate information (RAG), and a fourth carries out tasks (tools/workflows).
Capturing and Preparing User Input
Every interaction begins with user input, which can be text or voice. When a user types a message, the system cleans and normalizes the text. This includes removing unnecessary spaces, detecting the language, and attaching metadata such as the user’s ID, the device used, the time of the message, and the platform. For example, if you type, “Can I reschedule my dentist appointment?” the AI knows who you are and the context in which you are asking.
If the user speaks, Automatic Speech Recognition (ASR) converts the audio into text. The system also detects when you finish speaking and assigns a confidence score to ensure the transcription is accurate. For instance, if you say, “I need to move my appointment,” the AI converts it to text and captures timing and details so it can respond reliably.
Think of this step like a receptionist who not only takes your message but also notes who you are, when you called, and how you reached them.
The Orchestration and State Layer (The Control Center)
The orchestration and state layer is the central command of the AI system. While the LLM is excellent at understanding and generating language, it doesn’t inherently manage conversation history, track task progress, or interact with external systems. The orchestration layer makes sure that every interaction is coherent, contextually aware, and goal-directed.
For example, if you asked the AI yesterday to book a dentist appointment and today you say or text to reschedule such as, “Actually, make it next Friday,” the orchestration layer allows the AI to remember your previous request, your preferences, and the current step of the booking workflow. This ensures that the conversation flows naturally without requiring you to repeat details.
The orchestration layer also decides how each message should be handled. If the user asks a simple question, like “What are the clinic hours?” the AI can respond directly using the LLM. If the request involves a workflow, such as “Reschedule my appointment,” the AI follows structured steps like verifying identity, checking availability, and confirming the new time. When the request requires a tool or API action, such as checking a calendar for open slots, the orchestration layer plans the external call and passes the results back to the AI.
Think of the orchestration layer as a project manager coordinating a team of experts. It remembers what has already been done, decides what each team member should do next, and ensures tasks are completed efficiently, while the LLM acts as the skilled specialist carrying out the responses.
Grounding Responses with Knowledge (RAG)
To ensure accurate, up-to-date answers, conversational AI often uses Retrieval-Augmented Generation (RAG).
For example, if you ask, “What documents do I need for a new appointment?” AI retrieves the latest clinic policies or internal documentation and uses that information to formulate a response.
Think of this as consulting a current manual or database before giving advice, rather than relying solely on memory. This ensures responses are both accurate and trustworthy.
Before responding, the AI receives a carefully structured prompt that contains:
- Its role and persona, such as “You are a friendly clinic assistant.”
- Conversation history and summaries of prior interactions.
- Knowledge retrieved from documents or databases via RAG.
- User-specific information, like past appointments or preferences.
- Business rules and safety instructions.
- The latest user message.
For example, if you ask, “Can I reschedule my appointment to next Thursday?” the AI sees your past booking, current availability, and scheduling rules. It then crafts a response that is accurate, context-aware, and policy-compliant.
This is similar to a chef following a recipe with all ingredients and instructions in front of them, ensuring the dish is perfect.
Taking Actions with Tools and Workflows
Conversational AI can perform real-world actions by connecting to external systems and following structured workflows.
For example, when rescheduling an appointment, the AI generates a request to check available slots. The system validates permissions and constraints, queries the calendar, and updates your booking. A workflow might involve greeting the user, collecting information, verifying identity, performing the action, summarizing results, and offering next steps.
This is like an assistant who not only understands your request but also executes it correctly while following rules and confirming the results.
Generating and Delivering Responses
Once the AI determines what to say, it delivers the response in the appropriate format:
- Text: The response is formatted, sensitive information is encrypted, and the message is sent.
- Voice: Text is converted into natural-sounding audio using Text-to-Speech (TTS). The system manages tone, style, speed, and interruptions so users can speak naturally while the AI responds.
For instance, if you say, “Change my appointment to Friday,” the AI might reply, “Sure! Your appointment is now Friday at 10 AM,” spoken in a clear, natural voice.
Monitoring, Testing, and Continuous Improvement
Modern conversational AI systems improve through structured observation, not passive learning. Every interaction is logged end-to-end: user inputs, ASR outputs, LLM prompts and completions, retrieved knowledge, tool calls, and final responses. These logs feed continuous monitoring across three dimensions:
- Quality metrics: Task completion, error and fallback rates, hallucination incidents, and user satisfaction (CSAT)
- Behavioral metrics: Escalation to human agents, retries, and abandonment or drop-off points
- Performance metrics: Latency, throughput, and infrastructure cost
Latency is treated as a core quality signal because it directly shapes how responsive the assistant feels. Teams monitor both end-to-end latency (user input to response playback/rendering) and component-level latency across ASR, orchestration/LLM reasoning, retrieval, tool calls, and TTS. For voice interactions in particular, sustained delays beyond roughly one second lead to interruptions, repeated inputs, or abandonment; even when answers are correct.
Scenario-based testing and regression suites ensure the assistant follows policies, maintains tone, and behaves correctly across edge cases without introducing latency regressions. When metrics drift, such as higher p95 latency after a model update or slower retrieval after a knowledge-base expansion teams can quickly pinpoint the bottleneck and adjust prompts, workflows, models, or infrastructure. This creates a continuous feedback loop that improves reliability and responsiveness over time.
Optimizing for Cost and Speed
Teams that build and deploy conversational AI at scale must optimize speed, quality, and cost together rather than in isolation. Systems are designed around a practical latency budget that keeps interactions responsive while controlling compute spend.
Common optimization strategies include:
Model routing
- Simple, well-understood queries are handled by smaller, faster models
- Complex or high-stakes requests are routed to larger, more capable models
- Distillation and quantization are applied where possible to reduce inference time and cost
Context and retrieval efficiency
- Long conversations are summarized instead of passing full histories into every turn
- RAG retrieval is tightened i.e. fewer documents, shorter passages, faster indexes in order to reduce prompt size and response time
- Prompts are kept concise to avoid unnecessary attention and compute overhead
Pipeline and experience optimization
- Streaming ASR, generation, and TTS so users see or hear partial responses while processing continues
- Overlapping stages for example, starting LLM reasoning on partial ASR results
- Caching responses to popular questions to eliminate repeated inference entirely
For example, a question like “What time does the clinic open?” can be answered instantly using a small model or cached response. In contrast, rescheduling an appointment where factoring in availability, rules, and confirmation may invoke a larger model and multiple tools, accepting slightly higher latency in exchange for correctness and reliability.
By continuously measuring how each optimization impacts latency, answer quality, and cost, teams can make informed trade-offs and keep the assistant fast, trustworthy, and economical as usage scales.
Conversational AI in Action: A Working Example
Imagine calling a clinic to move your dentist appointment.
The AI first converts your voice to text using ASR. The orchestration layer retrieves your past appointments and workflow state. Knowledge about scheduling rules is fetched through RAG. The AI determines the next steps and interacts with the calendar system to find available slots. It confirms the new appointment, and TTS reads the confirmation aloud. If the request becomes complex, the conversation is escalated to a human agent with full context preserved.
This seamless experience works because orchestration, LLMs, knowledge retrieval, workflows, and voice technologies all function together like a well-coordinated team.
Conversational AI combines conversation memory, intelligent decision-making, accurate knowledge retrieval, and actionable workflows into a single, human-like system. Through monitoring and continuous improvement, it becomes smarter, faster, and more reliable over time.
Our 24/7 Conversational AI Agents
Banking
Conversational AI in banking that handles account servicing, payments, and lending queries in real time...
Sales
Reduce friction, speed resolution, and scale 24/7 sales experiences. Run full workflows through...
Contact Center
Round the clock support with a human touch. Run full workflows through conversational ai technology...
Marketing
AI-powered conversational AI marketing chatbots and agents to deliver a more personalized customer experience...
Logistics
Streamlines logistics and supply chain operations with real time tracking, cost savings, multilingual support, and...
Education
Personalized learning, faster outcomes, higher engagement, scalable support, and measurable academic performance gains.
Finance
Improves efficiency, reduces costs, enhances CX, ensures compliance, and scales personalized...
Government
Transform government services through automation, improve efficiency, accessibility, citizen satisfaction, and...
BPO
Boosts BPO efficiency, scalability, and CX while reducing costs, improving resolution rates, and enhancing agent productivity.
Manufacturing
Boosts OEE, reduces MTTR, automates workflows, enhances productivity, and delivers real-time insights across...
Games
Drives retention, immersion, automation, and monetization through scalable, real-time, personalized player interactions...
Airlines
Reduces costs, accelerates support, boosts satisfaction, enables 24/7 multilingual service, along with...
Plumbers
Helps capture leads, automate bookings, reduce no-shows, improve response times, and increase overall efficiency.
Media
Boosts engagement, drives revenue, automates workflows, and delivers personalized, scalable audience...
Dealerships
Turn calls into booked appointments and qualified leads - delivering higher coverage, less workload, and...
Insurance
Conversational AI in insurance automates claims intake, personalizes policy support, and...
E-commerce
Automate order status, returns, and FAQs with natural-sounding AI voice agents. Faster answers...
Customer Support
Conversational AI for customer support handles queries across chat, voice, and messaging - 24/7, in natural language...
Telecom
Answer every call instantly, resolve billing and network issues, cut handle time, and turn interactions into advantages
Hotels
Boosts bookings, guest satisfaction, efficiency, personalization, multilingual support, and operational performance...
HR & Recruiting
Answer PTO and leave, benefits and payroll questions, policy FAQs, onboarding check-ins, employee...





