
Get in touch with us
Improve your content production and save costs. A member of our team will be in touch soon
Compare Murf Falcon with leading TTS APIs using real-world benchmarks. Explore end-to-end latency, global consistency, voice quality, and cost to evaluate performance under real production conditions.
Text-To-Speech (TTS) systems operate within a complex set of trade-offs. They must produce speech that is expressive and humanlike, maintain very low latency, and do so within stringent cost and scalability limits. Improvements in one area, such as expressiveness or naturalness, often lead to inefficiencies in latency or concurrency. Balancing these factors requires more than incremental optimization. It calls for a fundamental rethinking of model architecture, data preprocessing, and inference strategy.
Murf Falcon introduces a new approach to streaming TTS.

Compute Efficient proprietary neural architecture outperforms much larger systems in context awareness , while delivering the speed benefits of a smaller model.
.webp)
Edge-level deployment minimizes network hop variability, ensuring consistent low latency across regions.
.webp)
Dynamic selection of cost-efficient GPU infrastructure available in each location, optimizes for both performance and cost.
This combination of architectural efficiency and intelligent deployment delivers significant latency improvements while reducing the overall token-processing cost of the model, making it exceptionally efficient across every parameter.
To demonstrate this, we benchmarked Murf Falcon against leading TTS APIs on both latency and voice quality. We plotted the benchmark data on efficiency quadrants to determine which model achieved the best balance of speed, quality, and cost in production.
1. Latency
This study measured time-to-first-audio (TTFA) for Murf Falcon and leading TTS APIs, including Eleven Labs, Open AI, Deepgram and Cartesia across multiple global regions to evaluate latency consistency and network variability.
TTFA is defined as the delay between the initiation of a synthesis request and the receipt of the first audio frame. We believe end to end latency is a better measure of responsiveness because it is what customers experience and is independently verifiable.
Using apiping.io, a geo-distributed API relay, identical streaming TTS requests were triggered for each API; Murf Falcon, Eleven Labs Flash v2.5, OpenAI 4o-mini-TTS, Cartesia Sonic Turbo and Deepgram Aura 2 from 33 global edge locations.
The system recorded DNS resolution, connection setup, TLS handshake, TTFA, and total response time. Both per-region and average latencies were measured to assess performance consistency.
Average latency denotes the mean time-to-first-audio measured across 33 global locations. By sampling multiple instances, this metric provides a robust estimate of the end-to-end latency typically experienced in real-world production environments.
When measured globally, Murf Falcon delivers an average TTFA of 130ms, setting the benchmark for real-world performance. Falcon is 44% faster than the next fastest model, Cartesia Sonic Turbo, and is significantly ahead of Eleven Labs and Deepgram.
In production, Falcon delivers the fastest text-to-speech performance.
.webp)
Voice agents serve users across the globe, so TTS latency performance must hold consistently across geographies, not just at a single test location.
Across key regions, Murf Falcon consistently delivers around 130ms time-to-first-audio. In head-to-head benchmarks, Falcon leads in 9 of 10 key business centers. It outperforms Eleven Labs and Deepgram in all 10 regions, and Cartesia in 9 of 10.
| Region |
 Falcon
Falcon
|
|
|
 Sonic Turbo
Sonic Turbo
|
 Aura 2
Aura 2
|
Murf Falcon's Ranking |
|---|---|---|---|---|---|---|
 N. Virginia N. Virginia |
135 | 189 | 431 | 142 | 192 |  1 1 |
| Ohio |
126 | 175 | 477 | 121 | 203 |  2 2 |
 Mumbai Mumbai |
108 | 437 | 545 | 170 | 393 | 1 |
 London London |
112 | 274 | 325 | 278 | 265 | 1 |
 Frankfurt Frankfurt |
116 | 265 | 345 | 239 | 250 | 1 |
 Osaka Osaka |
121 | 291 | 494 | 780 | 258 | 1 |
 Calgary Calgary |
131 | 251 | 428 | 466 | 177 | 1 |
 Singapore Singapore |
164 | 355 | 984 | 477 | 377 | 1 |
 Seoul Seoul |
114 | 325 | 478 | 267 | 272 | 1 |
 Melbourne Melbourne |
128 | 369 | 526 | 310 | 297 | 1 |
It is not enough for latency to be low, it must also be consistently delivered.
Latency consistency is measured using the Coefficient of Variance (CoV), which quantifies how much latency fluctuates across geographies. A lower CoV indicates greater consistency and stability in performance.
Murf Falcon records the lowest CoV of 0.17 among all models, demonstrating that it is not only the fastest but also the most predictable and stable text-to-speech system in production.

2. Voice Quality
We benchmarked Murf Falcon’s voice quality across multiple languages, comparing it against leading text-to-speech models using the Voice Quality Metric (VQM).
VQM is a purpose-built evaluation metric for voice agents. It provides a unified score that measures how natural, accurate, and reliable a voice sounds in real-world production. Instead of asking “Does it sound nice?”, VQM asks, “Does it say the right thing, in the right way, across complex, real-world inputs?”
Voice agents often handle critical information such as prices, health data, IDs, or timelines, where even a single mispronounced unit or digit can cause confusion or, in some cases, serious errors.
The Voice Quality Metric combines five distinct sub-metrics: Naturalness, Numerical Accuracy, Domain Accuracy, Multilingual Accuracy, and Contextual Accuracy. Each sub-metric is normalized on a 0–1 scale, then weighted and aggregated to generate a final composite score.
.webp)
We conducted comprehensive evaluations across all sub-metrics to arrive at the aggregate VQM score.
This study measured speech naturalness using UTMOS (Utokyo MOS), a neural MOS predictor developed by UTokyo SaruLab and trained on human-rated speech datasets. UTMOS estimates perceived naturalness on a 1–5 scale and has shown high correlation with human judgments in large-scale evaluations such as VoiceMOS 2022, making it suitable for automated benchmarking.
Each TTS model’s outputs were evaluated with UTMOS after preprocessing audio to the model’s native mono sample rate. Predictions were computed for every sample, and the median score per model was used to minimize outlier effects. Scores were normalized to a 0–1 scale by dividing by 5.
The test set comprised 3000 sentences ranging from 3–12 seconds, representing typical voice-agent interactions such as prompts, confirmations, and short explanations.
Language distribution: 200 US English, 100 UK English, 100 Spanish, 100 Hindi, 100 French.
Thanks, John. For privacy, I can only discuss details with the patient. Do you happen to know Alex and can pass along a message?
.svg)
Murf Falcon achieved a median naturalness score of 0.7, outperforming Open AI, Cartesia and Deepgram and trailing slightly behind ElevenLabs at 0.73.

This study measured how accurately each TTS model verbalized numbers, digits, and measurement expressions in natural sentences. It covered currencies, quantities, dates, ranges, and units such as "$1.05", "37 °C", "2.5 kg", "120 km/h", "2025", "09:45", and "+1-415-555-0199".
Each model’s output was evaluated on its ability to correctly speak numeric and symbolic expressions across categories such as integers, decimals, dates, and digit sequences within mixed text–number contexts. Outputs were compared to canonical spoken forms (for example, “one dollar and five cents”), with regional variants accepted if clear and documented in the rubric. Accuracy was computed as the percentage of correctly rendered items, verified through blind human review, and then normalized to a 0–1 scale to enable aggregation with other metrics.
The test set comprised 75 short to medium-length sentences representing common real-world voice-agent interactions involving prices, weights, temperatures, percentages, and dosage units.
Your PPO health insurance claim for $2,347.89, submitted on 09/15/2025, has been partially approved with a deductible of $500 and a co-insurance rate of 20 percent.


With a normalized score of 0.8, Murf Falcon delivers the highest numerical accuracy, clearly surpassing all other evaluated models.
.webp)
This study measured how accurately TTS models pronounced technical terms, abbreviations, and acronyms common in professional, medical, and enterprise contexts, including items like API, ECG, OTP, UPI, Wi-Fi, and SpO₂.
Each model’s output was evaluated on pronunciation accuracy within contextual sentences from banking, healthcare, and enterprise domains. Ground truth was based on standardized spoken forms (e.g., “S-P-O-two,” “U-P-I”), with accepted variants like “Sequel” for SQL. Human reviewers validated the outputs through blind adjudication. Final accuracy was reported as the percentage of correctly pronounced terms and then normalized to a 0–1 scale to enable aggregation with other metrics.
The test set includes 60 short to medium-length sentences drawn from key professional domains:
Please send your resume to hr@infotech.in
With a normalized score of 0.83, Murf Falcon surpasses Eleven Labs and Cartesia, trailing behind Open AI and Deepgram by a small margin.

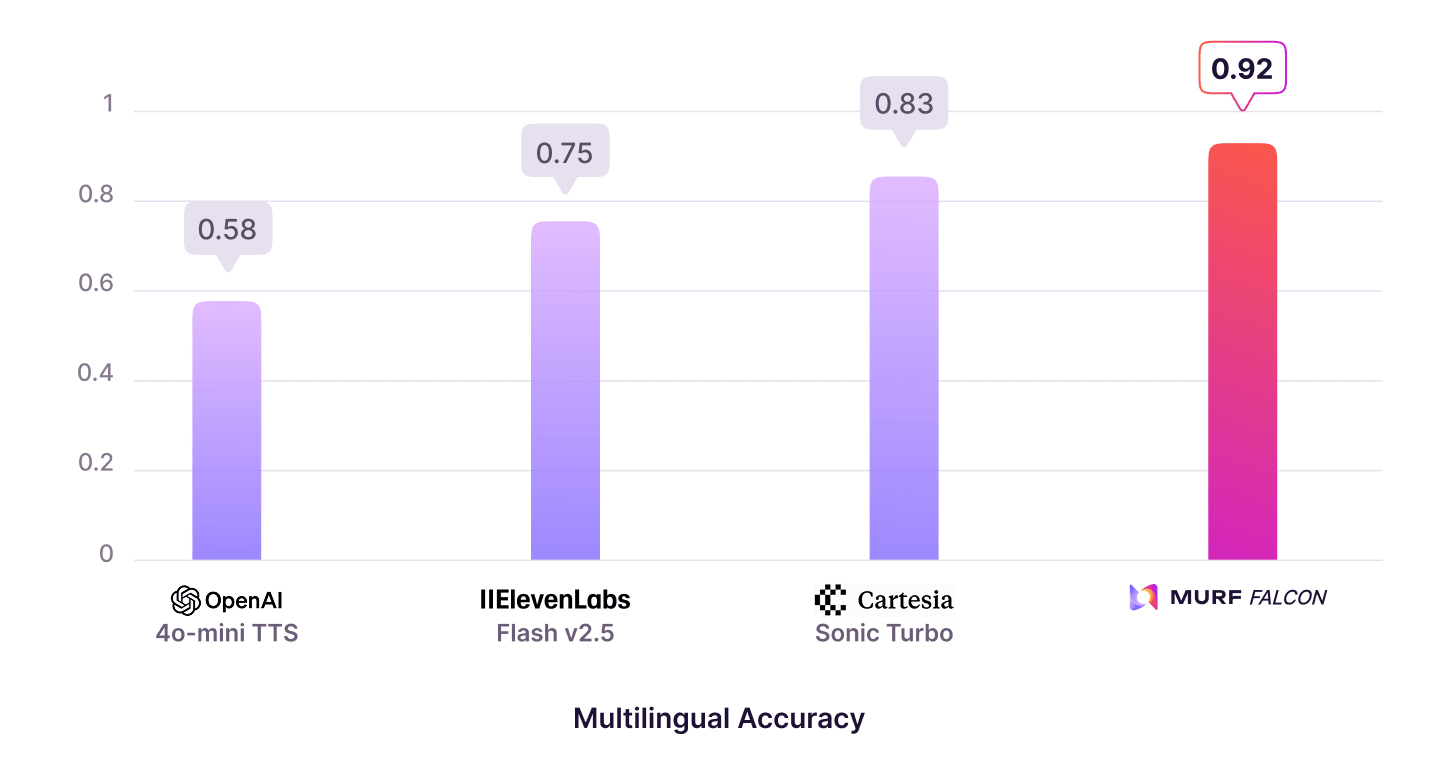
This study measured how well each TTS model maintained correct pronunciation and fluency in code-switched sentences, which are single utterances that mix languages such as “Let’s meet mañana at 5” or “Send it to ड्राइव please.”
Each model’s output was evaluated on its ability to switch smoothly between languages within a single utterance while preserving pronunciation and prosody. Evaluation focused on English sentences containing inline Hindi or Spanish phrases. Bilingual reviewers verified accuracy at the phoneme and word level. Final scores were computed as the percentage of correctly rendered code-switched items and then normalized to a 0 - 1 scale to enable aggregation with other metrics.
The dataset comprised 60 short to medium-length code-switched sentences in English–Hindi and English–Spanish, each reflecting natural conversational contexts with embedded foreign-language segments.
“आपकी last transaction ₹1,250 की थी, क्या आप उसे verify करना चाहेंगे?”
With a normalized score of 0.92, Falcon’s best-in-class multilingual model outperforms every other production model, making it ideal for real-world mixed-language conversations.
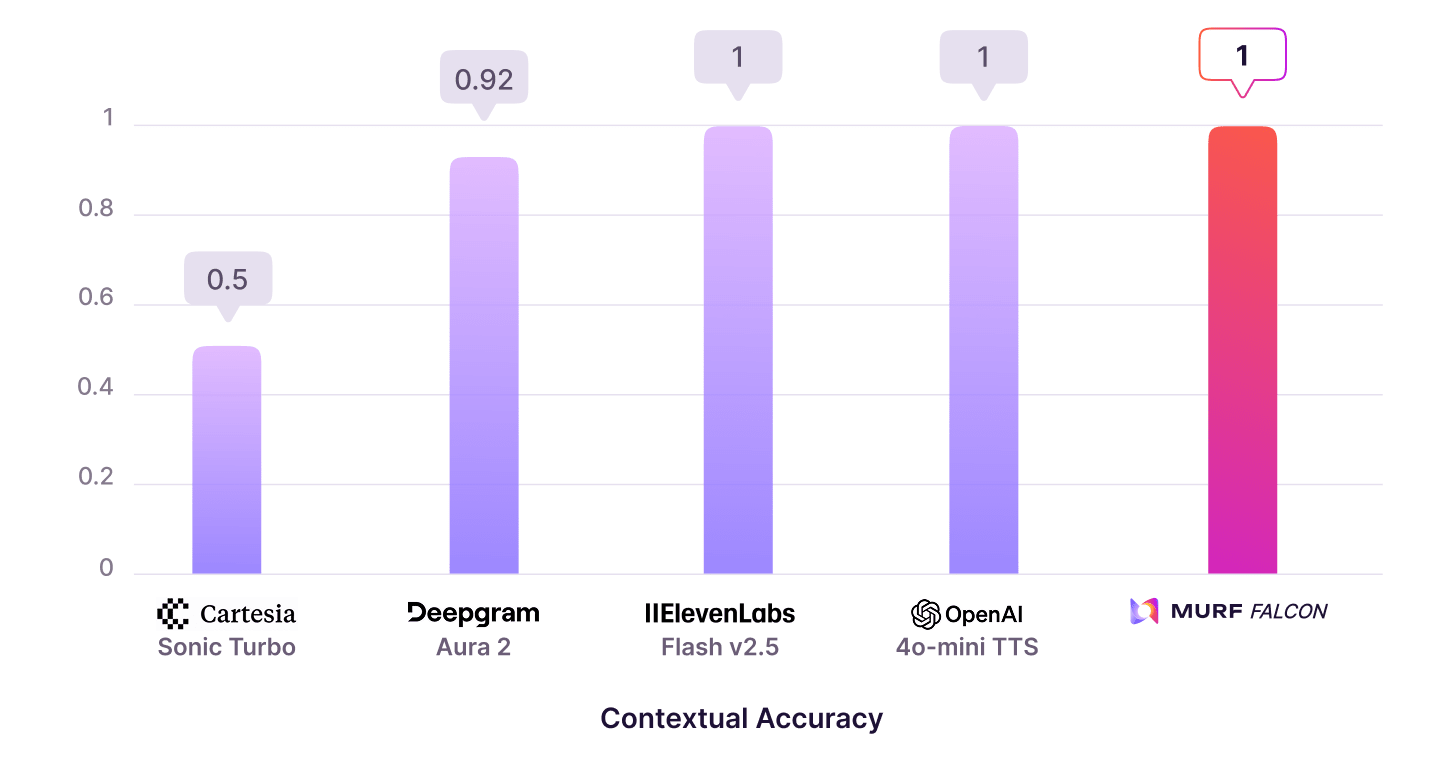
This study measured how well each TTS model pronounced homographs, words that share the same spelling but differ in pronunciation and meaning, such as lead (metal) vs lead (to guide) or read (past) vs read (present).
Each model’s output was evaluated on its ability to infer context and apply the correct pronunciation within short to medium-length sentences. The test set included examples such as lead, bow, row, wind, and minute, as well as stress-shift pairs like record (noun) and record (verb). Ground truth was defined at the phoneme level, and outputs were analyzed using forced alignment and ASR validation, with human adjudication to resolve ties. Final accuracy was reported as the percentage of correctly pronounced items and then normalized to a 0 - 1 scale to enable aggregation with other metrics.
The dataset comprised 60 contextual sentences designed to force disambiguation (for example, “They will lead the tour” vs “The pipe is made of lead”), each providing clear semantic cues requiring correct pronunciation for comprehension.
The microscope revealed a minute organism.
Murf Falcon, ElevenLabs, and OpenAI perform equally well on this test, ranking among the top tier in contextual accuracy and in distinguishing between homographs.
The individual sub-scores are aggregated using assigned weightages, as shown below, to arrive at a consolidated VQM score.

Murf Falcon achieves a VQM score of 0.77, setting a new benchmark in this category. This reflects superior performance not only in voice naturalness but also in overall accuracy and model reliability, outperforming the next best system, by a significant margin.

Most TTS models optimize for a single parameter - voice quality, latency, or cost. While that may work for content generation, voice agents require strength across all three. Using the benchmark data obtained earlier, we plotted efficiency quadrants to identify models that deliver on all dimensions versus those that will lead to trade-offs.
We plotted the VQM scores of tested TTS models against their cost per generated minute. Murf Falcon stands out in the most efficient zone, delivering high voice quality at nearly one-third the cost. Competing models exhibit clear trade-offs and are often not cost-efficient.
%20(1).webp)
When we plotted time-to-first-audio against VQM scores for the tested TTS models, Murf Falcon once again landed in the most efficient quadrant, combining ultra-low latency with high perceptual quality. Other models required compromises between the two.

This is why we call Falcon the consistently fastest and most efficient text-to-speech API in production, delivering 130 ms time-to-first-audio, industry-leading VQM scores, and stability proven across geographies, all at a fraction of the cost at just 1 cent per minute.
Keeping your data safe





