The Fastest, Most Efficient
Text-to-Speech API for Building Voice Agents
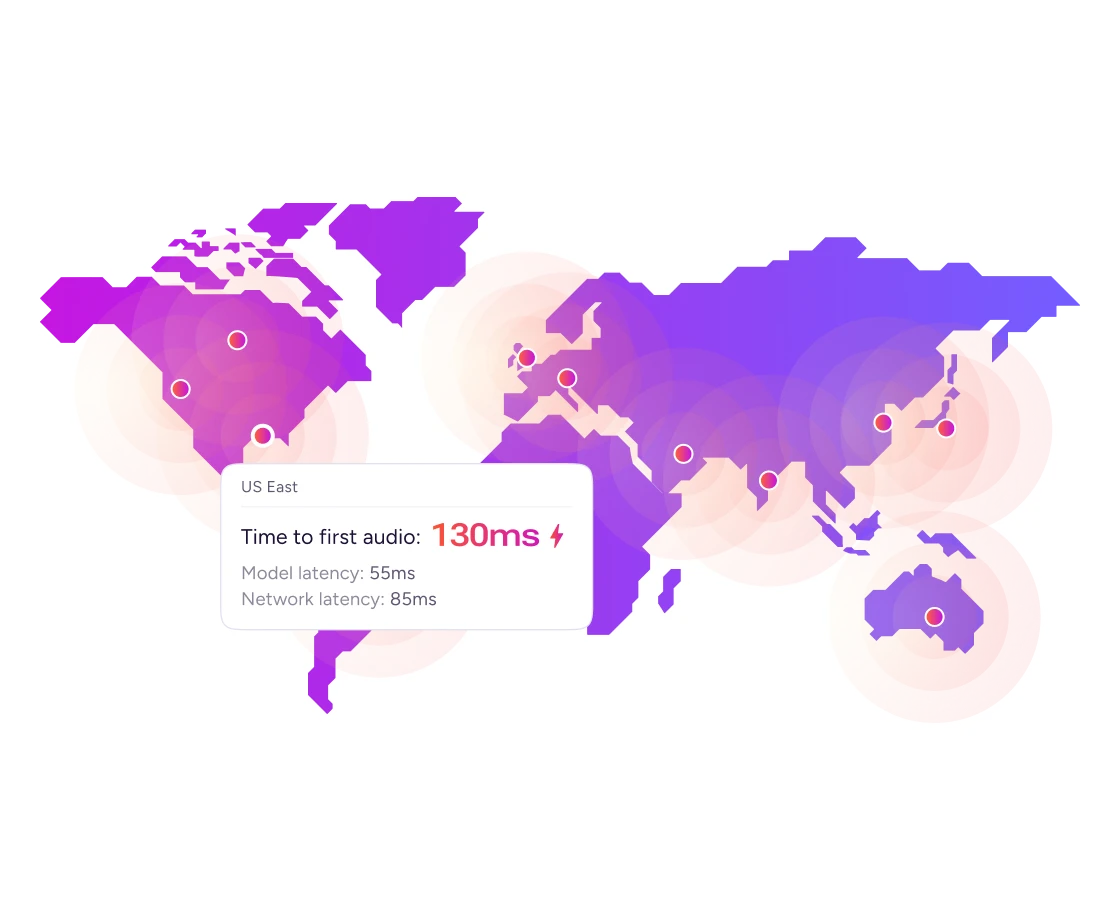
55ms model latency. Truly multilingual. Up to 10,000 concurrent calls. 1cent/minute.
Murf Falcon helps you build voice agents that are ultra-fast, expressive, scalable and significantly
cost-efficient, all at once.
.webp)
.svg)

.svg)
.svg)

.webp)
.webp)

.webp)
.webp)

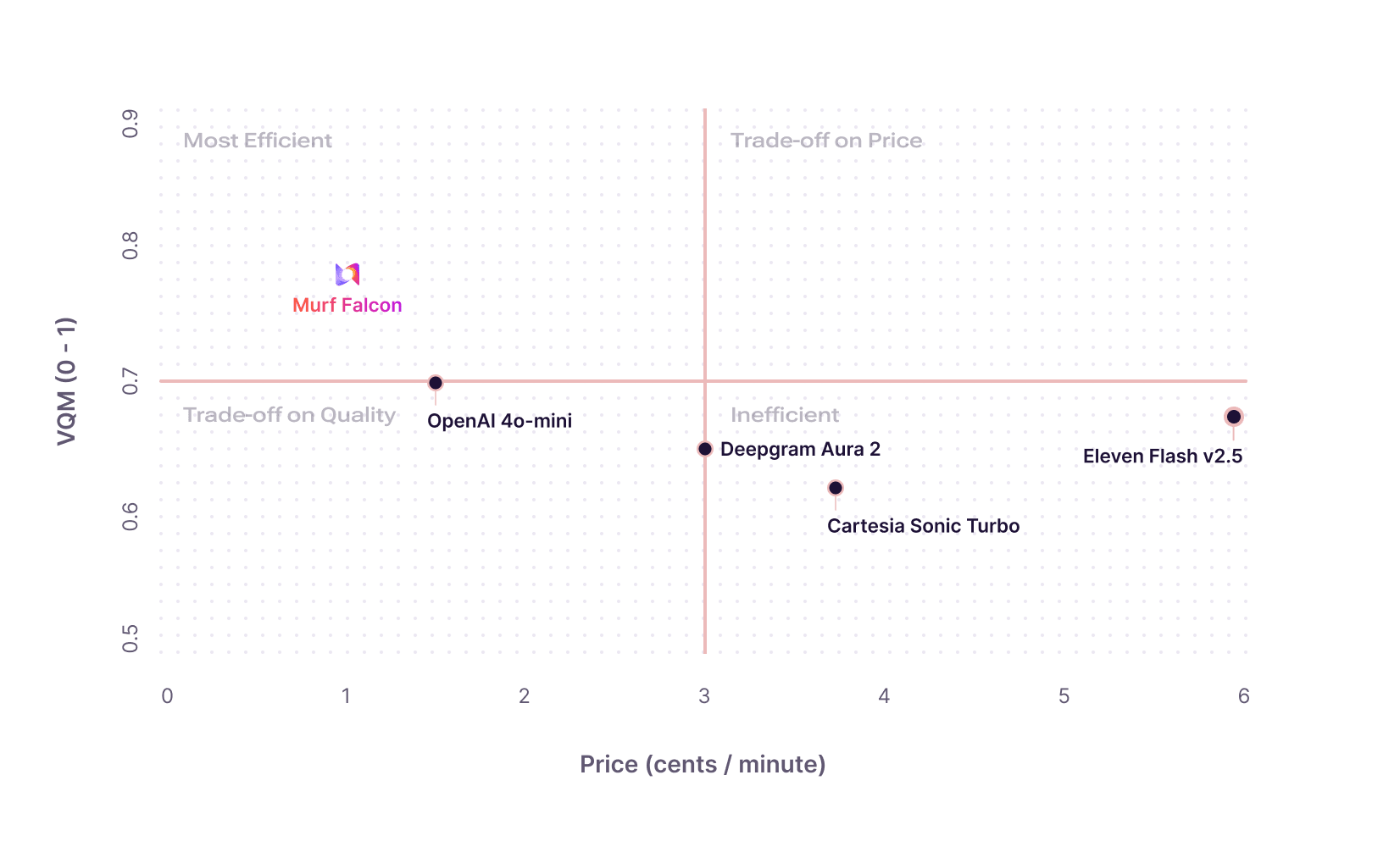
Falcon Delivers All-Round Efficiency Across Multiple Dimensions
Text-to-speech models are typically one-dimensional. They either excel at voice quality, latency or cost. This works for content creation but voice agents demand optimal performance across all dimensions. That’s where Falcon soars.
.webp)
.webp)
.webp)
.webp)
.webp)
How Falcon Delivers
Overall Efficiency
We rebuilt the entire stack to solve the challenges that compromise speed, cost and accuracy.
Lightweight Architecture Leads to Low Latency
Falcon uses a compute-efficient proprietary neural architecture that outperforms much larger systems in context awareness, while delivering the speed benefits of a smaller model.

Edge Deployment Results in Lower Latency and Costs
Edge deployment reduces the variability in network hop times resulting in consistent and lower latency. The system also picks the most cost-efficient GPU in every region, keeping costs down.

Disentangled Representation Improves Native Fluency
Falcon encodes phonemes separately from voice, so switching language doesn’t drag unwanted accents. This preserves speaker consistency across languages, leading to better native fluency and code-mixing.
.webp)
Built on the Tech Stack Trusted by
10,000+ businesses






The Model That Outperforms Every Other Model in Production
Across technical, business and support parameters, Falcon beats every other model not just on paper,
but more importantly, in production.

.svg)
.svg)
Integrate Murf Falcon with Any Application in
Just Five Minutes

Quick Integration with API Endpoints
- RESTful API endpoints with predictable patterns
- Easy to combine with any service - Twilio, Anthropic or Discord
- Step-by-step tutorials for common use cases


Comprehensive SDKs Across Languages
- Production-ready Python SDK for quick, reliable integration
- Ready-to-use code examples in Java and cURL
- Type-safe by default for an enhanced developer experience
- Seamless integration with minimal setup

Multi-layered
Security Infrastructure

SOC 2 Type II Certification

ISO 27001 Certification

GDPR
Compliant
.webp)
HIPAA
Compliant

Service Beyond the Sale
After half a decade of building and shipping foundational models, we have worked through just about every challenge out there. We will be right there in the trenches with you.
Industry-Leading Customer Support
With an average chat response time of under 3 minutes, 24×7 availability and dedicated account managers, we are right there when you need us most.
Built to Evolve With You
From data residency to on-premise deployment to addition of new languages, we offer a flexible, customizable environment that adapts as you scale.
99.9% Uptime Commitment
We back it with real-time monitoring, redundant systems, and auto-scaling infrastructure to keep your workloads running without interruption.
Support for StartUps
Whether it’s through our Startup Incubator Program or visibility on our channels, we help early-stage teams build, scale, and get their voice heard.
150+ Professional Voices for Every Kind of Use Case
Powered by real voice actors who earn royalties for every selection, our catalog covers the full spectrum of voice agent use cases.










