Murf Translation Agent: Raising the Bar for Translation Quality in AI Dubbing
.webp)
Murf’s AI Dubbing is built for one clear purpose: to take your content global without losing clarity, tone, or impact.
With support for 40+ languages, precise duration matching, and natural-sounding voices, Murf helps keep your message intact while adapting it for new regions.
As we scaled with customers, we uncovered a crucial truth: Great dubbing doesn’t start with the voice. It starts with the translation. If the words are wrong, the best voice in the world can’t save your video. Even the most realistic AI voice sounds robotic or “uncanny” when it’s reading a clunky, literal script.
In this deep dive, we unpack the industry’s core translation problems, the customer insights that shaped our approach, and how Murf’s multi-layered, context-aware LLM translation agent with a dedicated “Judge” layer delivers higher-quality dubs, backed by rigorous MQM-based benchmarks against HeyGen and ElevenLabs.
Part 1: The Industry Gap and the Customer Insight

The Status Quo: Why “Good Enough” Fails
For the last decade, much of the localization industry has relied on Neural Machine Translation (NMT), the same underlying technology used by tools like Google Translate. NMT typically operates on a simple, linear premise: take a sentence in Language A and map it to Language B based on statistical probability.
This approach has a fatal flaw: it is context-blind.
Standard NMT engines don’t know who is speaking, who is listening, or what the video is about. They treat a medical safety warning with the same “weight” as a casual vlog. They don’t reason about audience, stakes, or brand voice; they just match patterns.
That leads to three recurring issues in AI dubbing:
- Lost Meaning and Detail
- Skipped lines or missing qualifiers
- “Hallucinated” phrases that never existed in the source
- Mistranslated domain-specific terminology
- Broken Tone and Brand Voice
- Switching between formal and informal address mid-video
- Over-literal translations that sound obviously machine-generated
- Style that doesn’t match the audience (e.g., C-suite vs. students)
- High Editing Overhead
- Localization teams fixing terminology inconsistencies across long videos
- Manual corrections for gender/number agreement and pronouns
- Rewrites needed just to make the script sound human and on-brand
The result: Many teams end up spending more time fixing “automated” output than they would have spent commissioning a traditional human dub.
What We Learned from Our Customers
When we interviewed our enterprise users, from L&D directors to marketing VPs and video teams, we identified a recurring, deeper need. They didn’t just want accurate words; they wanted context-aware adaptation.
- L&D Manager (Omission / completeness):
“If the translation drops even a small qualifier in a training module, the instruction changes. People learn the wrong thing and it becomes a compliance risk. I need zero omissions” - Localization QA Lead (gender / reference accuracy):
“If pronouns, gender, or roles flip, we misidentify the person on screen. That’s not a small error, it’s disrespectful and risky. I need a reference-accurate translation.” - Marketing VP (brand risk / intent drift):
“One bad word choice can add intent that was never there. That’s brand risk.” - Brand Manager (titles / proper nouns):
“If titles, designations, or company names get rewritten, the brand loses authority. Viewers trust us less. I need proper nouns and titles preserved.” - Video Editor (timing):
“If the Spanish script runs 30% longer, the voice has to rush. I need timing control.”
The message was clear: a generic 'text-in, text-out' button wasn’t enough. Customers needed a system that could understand context and make decisions, not just translate word-for-word
Part 2: Murf’s Reasoning-Based Translation Architecture
To bridge this gap, we moved beyond standard NMT and built a multi-stage pipeline powered by Large Language Models (LLMs). We treat translation as an agent task, not just a vocabulary task.
Concretely, Murf’s translation agent differs from standard MT in four key ways:
- It starts from clean, separated speech, not noisy mixed audio.
- It uses a context-aware LLM to adapt for use case, audience, and tone.
- It applies a second “Judge” LLM that reasons about meaning, coherence, and style before finalizing the script.
- It runs a final Duration Check to rewrite text for perfect timing.
All of this happens automatically, in seconds, at scale across large volumes of video content.
Step 1: Start with Clean Speech (Source Separation)
“Garbage in, garbage out.” Before we translate a single word, we clean your audio.
We use an in-house source separation model to isolate the speaker’s voice from background music, sound effects, and room noise.
Why this matters:
Standard translation tools get confused by background noise. They often try to “translate” the lyrics of a background song or interpret room echo as words. By stripping away the noise first, we ensure the system works with clean text based only on what was actually said.
Step 2: Context-Aware Translation
Next, the clean speech enters our first Large Language Model (LLM) layer. This layer doesn’t just swap source words for target-language words. It analyzes context cues such as:
- Use case: Is this a corporate L&D module, a technical product explainer, or a snappy social media ad?
- Audience: Are we speaking to C-suite executives, developers, students, or the general public?
- Tone: Should the output be formal, instructional, conversational, or persuasive?
This ensures the translation doesn’t just convey the meaning: it matches the vibe and expectations of your specific audience and use case.
Step 3: The “Judge Layer” (Murf’s Secret Weapon)
.webp)
This is where Murf leaves standard AI translation workflows behind.
Most AI translators work sentence by sentence, often forgetting what they “said” ten seconds ago. At Murf, once the initial translation is generated, a second LLM acts as a Judge.
The Judge doesn’t just spellcheck. It simulates the workflow of a human editor, running a rigorous four-point audit on every segment:
- The “Meaning” Check
- Goal: Ensure the translation is fully accurate, complete, and natural.
- Audit: Did we add fluff? Did we miss a sentence? Is the meaning distorted?
- The “Context” Check
- Goal: Ensure tone and style fit the specific use case and target audience.
- Audit: If the audience is developers, did we use precise technical terms? If the use case is marketing, is the tone persuasive?
- The “Coherence” Check (Crucial for Long Videos)
- Goal: Maintain discourse-level coherence across the whole video.
- Audit: Did we translate key terms consistently, or did we flip-flop between different words?
- The “Reasoning” Process
Before approving the text, the Judge “thinks” step by step internally:
“I need to understand the full nuance of the source… Compare it to the translation… Check if the formality matches the C-suite audience… Verify that we didn’t use jargon for a general audience…”
Step 4: Duration Adaptation (The "Timing" Loop)
.webp)
Once the translation is accurate, we solve the hardest constraint in video dubbing: Time.
Languages like Spanish or German can be 20–30% longer than English. Standard dubbing tools simply speed up the voice to force the text to fit, leading to an unnatural "rushed" effect.
Murf does not force the fit. We re-translate.
If the system detects a duration mismatch:
- The segment is flagged and passed back to the re-translation layer.
- The model is given a specific constraint: “Rewrite this sentence to be 15% shorter, without losing the context, tone, or key technical terms.”
- The system generates a concise version that fits the original timeline perfectly.
This ensures your video maintains cinematic pacing without the AI voice ever sounding rushed or breathless.
By forcing reasoning and checks before the voice is generated, Murf reduces the awkward phrasing, missing context, and meaning drift that commonly plague standard workflows.
Part 3: How We Measured Translation Quality (The Methodology)
To fairly compare Murf against HeyGen and ElevenLabs, we couldn't rely on "vibes" or internal opinions. We needed a rigorous, industry-recognized standard.
We chose MQM (Multidimensional Quality Metrics) the gold standard framework used by professional localization experts to objectively grade translation quality.
Why We Chose MQM (and Rejected BLEU)
In the AI industry, many teams cite BLEU, short for Bilingual Evaluation Understudy which is a classic automated metric from machine translation that compares a model’s output to a reference translation by checking how much the wording overlaps (often via n-gram matches).
- The Problem with BLEU: It primarily measures how many words overlap with a reference text. It is a game of "word matching."
- The Flaw: A BLEU score cannot tell the difference between a harmless stylistic choice and a critical safety error. It treats a typo the same way it treats a dangerous mistranslation.
We rejected those metrics in favor of MQM because it is human-centric. Instead of just counting matching words, MQM counts actual errors and their severity, giving us a true picture of how a human audience perceives the video.
How MQM Scoring Works
MQM works like a rigorous exam. Every translation starts with a perfect score of 100. Reviewers then tag every error in the output and deduct points based on two factors: Category and Severity.
1. The Error Categories
- Mistranslation: The meaning is wrong (e.g., “weekly” becomes “daily”).
- Omission/Addition: Leaving out content or inventing words that weren’t there.
- Grammar/Spelling: Typos, wrong gender agreement, or broken syntax.
- Style/Terminology: Using slang in a legal document, or overly formal language in a casual video.
2. The Severity Weights
Not all mistakes are created equal. We deduct points based on how much the error damages the viewer's experience:
- Minor (–1 point): Slight awkwardness; doesn’t confuse the viewer.
- Major (–5 points): Hard to understand or change the meaning.
- Critical (–10 points): Dangerous or unacceptable errors—misleading instructions, offensive cultural mistakes, or anything that could cause real-world harm.
The Formula:
MQM Score = 100 – (Sum of penalty points)
Higher is better. A score close to 100 indicates near-human quality.
The Benchmark Setup
To ensure an unbiased test, we adhered to a strict protocol:
- Diverse Dataset: We curated a collection of 80 publicly available videos spanning multiple real-world use cases including Public Announcements, Entertainment, Corporate Training, Product Explainers, and Marketing to reflect the kinds of content teams actually dub at scale.
- Diverse Languages: Our dataset includes videos with multiple source and target languagesincluding English, Spanish, Hindi, Dutch, German, Chinese, Russian, and French enabling evaluation across a mix of language families and dubbing constraints such as tone, terminology, and timing.
Part 4: Results
We ran the benchmark across multiple languages and content types using MQM scoring. Here are the average MQM scores we observed:
-1%20(2).webp)
These results aren’t accidental: they reflect consistent differences in how each system handles the translation problems that most often break AI dubbing: mistranslation, omission, meaning drift, and consistency.
A step-by-step example (including the full error log and how penalties add up) is included in the Appendix.
ElevenLabs (Score: 88) — Fluent, but More Meaning Drift and Omissions
ElevenLabs can sound natural, but in our testing the translation layer showed more frequent issues like:
- Meaning shifts (especially around timeframes, qualifiers, and logic)
- Omissions where context or descriptors drop out, reducing completeness
Inconsistency across segments that affects coherence in longer videos
Impact: The dub may sound smooth, but it can become incomplete or less precise. This raises QA costs in professional settings.
HeyGen (Score: 89) — Good, but Inconsistent
HeyGen often produces output that is broadly understandable, but it’s more likely to require review because of recurring issues such as:
- Mistranslations that subtly (or sometimes significantly) change the intended meaning
- Idioms and figurative language being interpreted too literally, leading to tone or intent drift
- Terminology and style inconsistencies that make long-form content feel “translated” rather than native
- Occasional gender/role mismatches that can distort who is being described
Impact: The core message usually comes through, but the output can feel off-brand or unreliable without a human pass.
Murf (Score: 92) — Most Reliable for Professional Use
Murf scored highest due to its multi-stage approach (cleaner input, context-aware translation, and a Judge layer that checks meaning, tone, and coherence before final output):
- Fewer meaning-altering errors
- Lower omission rates
- More consistent terminology and tone across segments
Impact: More publish-ready dubs with less manual correction, especially for high-stakes and brand-sensitive content.
See the Difference Yourself
Numbers are one thing, but hearing is believing. Watch the same segment dubbed by all three platforms below.
Issue 1 : Mistranslation (Meaning Drift / Unsafe Interpretation)
What the source meant: A harmless sports metaphor (“touch and tease”) used playfully in context. Also in the same scene, the timeline line is “18 years since …” (i.e., 18 years have passed since that event).
- HeyGen: Rendered the phrase as “छुअन और छेड़छाड़,” where “छेड़छाड़” can imply harassment/tampering, changing intent.
- ElevenLabs: Introduced a separate meaning error elsewhere in the same scene: “18 years since…” → “18 साल पहले…” (“18 years ago”), changing timeframe logic.
Why this matters: One word can change tone from playful to inappropriate. A timeframe shift can make a claim unreliable.
Customer lens: This matches what our Marketing VP warned us about: intent drift and logic drift create brand and credibility risk.
Issue 2 : Omission (Dropped Meaning / Missing Context)
What the source meant: Identifying a speaker with authority: “Microsoft CEO Satya Nadella…”
- ElevenLabs: Dropped “Microsoft CEO,” leaving only the name.
Why this matters: Without the title, global viewers lose context for why this person matters weakening clarity and authority.
Customer lens: This is exactly what our L&D Manager told us: dropping designations breaks credibility.
Issue 3: Grammar & Agreement (Gender / Role Consistency)
What the source meant: Role descriptions that must match the person being described. This includes correct gender and role form.
- HeyGen: Rendered male-context roles in feminine forms (e.g., “singer” → “गायिका”), misidentifying the subject.
Why this matters: These aren’t “stylistic” issues — they misidentify people and alter facts, which can be disrespectful and unsafe to publish.
Customer lens: This maps directly to our Localization QA Lead concerns: reference accuracy and completeness aren’t optional.
Issue 4 : Terminology & Reference Accuracy
What the source meant: A specific organization name: “平价集团” (FairPrice Group).
- ElevenLabs: Translated it descriptively as “Affordable Group,” losing the entity’s proper name.
Why this matters: This is an identity error, not a style preference. Wrong proper nouns can misattribute brands and create compliance/publishing risk.
Customer lens: This is what our Brand Manager flagged: names and titles must survive translation intact.
Issue 5: Timing & Syncing Control
What the source meant: Product description lines landing on the correct on-screen moments.
- ElevenLabs: Showed timing drift when English lines came in shorter/longer than the performed pacing, creating audible stretching and visible sync mismatch.
Why this matters: In product videos, sync is perceived quality. Misalignment makes the video feel unpolished and can confuse viewers about key claims.
Customer lens: This is exactly what our Video Editor told us: timing control is non-negotiable.
Conclusion: Accuracy Builds Trust
When you dub a video, you’re asking a new audience to trust your brand. A mistranslation isn’t just a typo, it’s a broken promise to your customer.
While many tools stop at “good enough,” Murf’s multi-layered architecture ensures your message travels globally without baggage. You get global-ready dubs that sound native, protect your brand, and reduce manual QA time.
Whether it’s an internal training module or a high-stakes marketing campaign, accuracy is non-negotiable. Don’t let a bad translation ruin your global launch.
Appendix
To keep the benchmark transparent and reproducible, we didn’t rely on subjective “this sounds better” judgments. For every dubbed output, we created an MQM-style error log, assigned penalty points per error based on severity, then computed:
MQM Score = 100 − (Sum of penalty points)
Below is one complete worked example from our benchmark. We performed the same error logging and scoring for all other dub files included in the study, and then averaged the resulting MQM scores to report the platform-level results in Part 4.
A. Example file and final scores
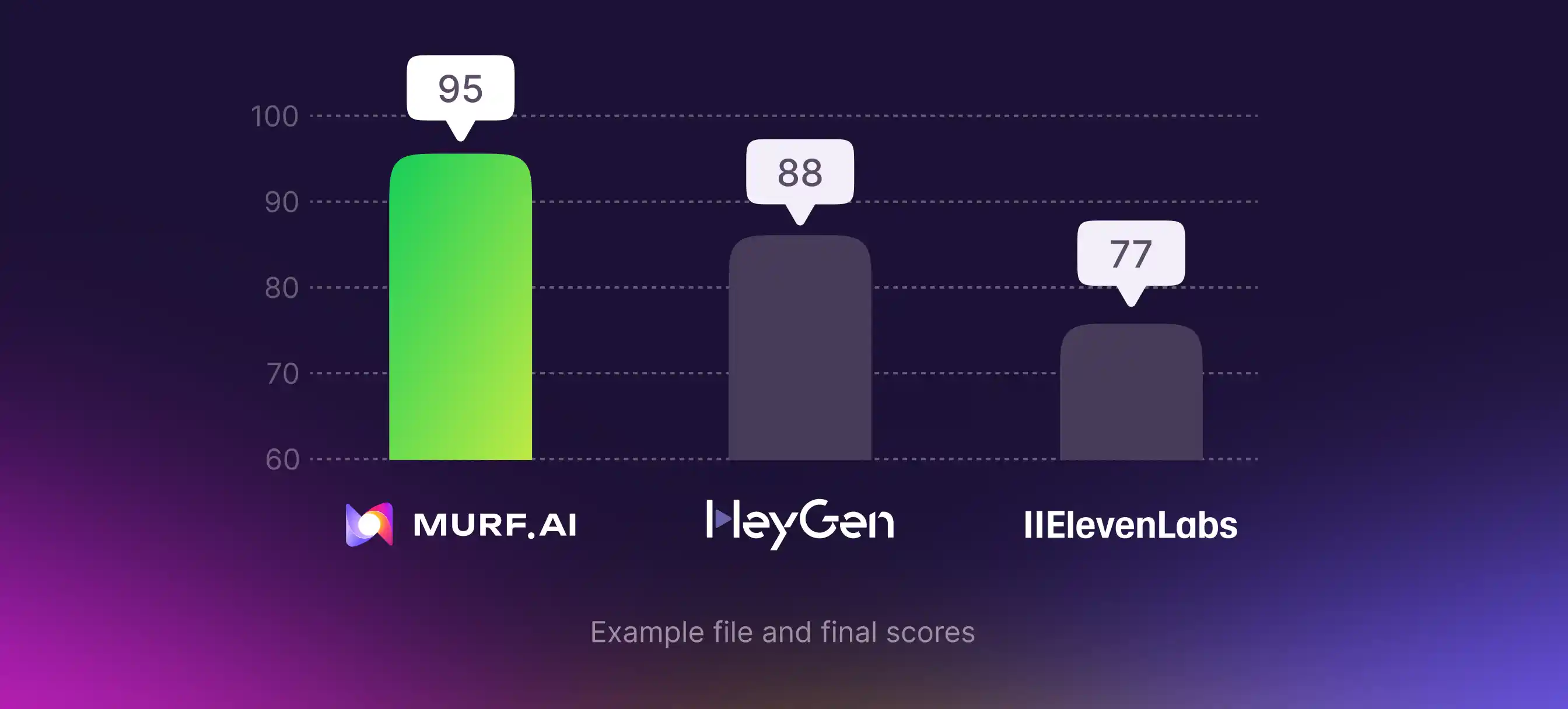
File evaluated: Video of Sundar Pichai Interview
B. Full error log and penalty totals (this one file)
Murf AI : Errors (Total penalty = 5 → MQM = 95)
Penalty sum: 1+1+1+1+1 = 5 → MQM = 100 − 5 = 95
HeyGen : Errors (Total penalty = 12 → MQM = 88)
Penalty sum: 5+5+1+1 = 12 → MQM = 100 − 12 = 88
ElevenLabs : Errors (Total penalty = 23 → MQM = 77)
Penalty sum: 1+5+5+1+5+5+1 = 23 → MQM = 100 − 23 = 77
C. How this connects to the headline benchmark scores
We repeated the same process (MQM-style error logging → sum of penalties → MQM = 100 − total penalties) across all videos, language pairs, and platforms in the benchmark. The scores shown in Part 4 (Murf: 92, HeyGen: 89, ElevenLabs: 88) are averages across the full set of 80 evaluated dubs. This appendix documents the calculation methodology and includes a fully worked example.
Below presents the Translation Benchmarking Results for all 80 files.




.webp)
.webp)