
![Murf Ai vs Hume AI: Tried Both & Here's the Winner [2026]](https://cdn.prod.website-files.com/675151245f2993547dbd5046/697b40a80054905f878479fb_69203d9f1eb2522a57ce34fb_Murf%2520Ai%2520vs%2520Hume%2520AI%2520Tried%2520Both%2520%2526%2520Here%2527s%2520the%2520Winner%2520%255B2025%255D.webp)
![Murf AI vs Cartesia: Tried Both & Here's the Winner [2026]](https://cdn.prod.website-files.com/675151245f2993547dbd5046/697b40a9c6be1ad11b5098cf_69203ce3526faed3810d11c1_Murf%2520Ai%2520vs%2520Cartesia%2520Tried%2520Both%2520%2526%2520Here%2527s%2520the%2520Winner%2520%255B2025%255D.webp)
![Hume AI vs Elevenlabs: Tried Both & Here's the Winner [2026]](https://cdn.prod.website-files.com/675151245f2993547dbd5046/697b40a3436c79a584f12967_69203bca2cd91887176f495b_Hume%2520AI%2520vs%2520Elevenlabs%2520Tried%2520Both%2520%2526%2520Here%2527s%2520the%2520Winner%2520%255B2025%255D.webp)
![Cartesia vs Elevenlabs: Tried Both & Here's the Winner [2026]](https://cdn.prod.website-files.com/675151245f2993547dbd5046/697b407fe35b527314ad856c_69203ae520e05df942cee6bf_Cartesia%2520vs%2520Elevenlabs%2520Tried%2520Both%2520%2526%2520Here%2527s%2520the%2520Winner%2520%255B2025%255D.webp)
Get in touch
Discover how we can improve your content production and help you save costs. A member of our team will reach out soon

Summarize the Blog using ChatGPT
AI-driven voices are revolutionizing how we interact with technology, providing a more natural and human-like communication experience. They are essential because they mimic human speech, understand context, and interpret language. From automating customer service interactions to crafting captivating content in entertainment and enhancing educational platforms with virtual tutors, AI voices are emerging as vital tools.
As AI voice technology becomes increasingly crucial in fields like entertainment, customer service, and education, knowing how to create a synthetic voice can be a valuable skill.
Two primary methods for creating an AI voice are using AI generators or building a custom voiceover from scratch. Each approach has advantages and challenges, catering to different needs and expertise levels.
Let's explore how to make an AI voice using voice technology and advanced custom techniques, offering step-by-step guides for each method.
AI voice generators convert text into realistic speech in just a few steps. They can help users create custom voiceovers for videos, create their own AI voice, or create personalized virtual assistants, acting as a tool for streamlining businesses and content creation.
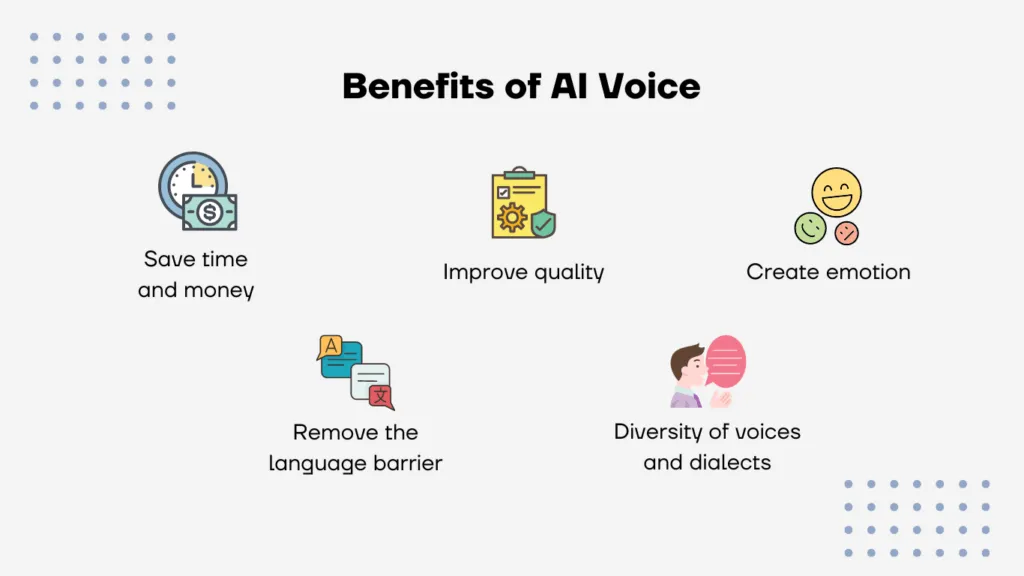
AI Voice Generators are innovative software applications that harness the power of artificial intelligence to transform text into speech that sounds remarkably natural.
These tools make it simple to create lifelike voices through text to speech (TTS), voice changers, and voice cloning. AI voice generators allow users to create natural sounding voices effortlessly; no advanced technical knowledge in machine learning or speech synthesis is needed. The ease and speed provided by AI generators stand out as one of their major benefits.
Why get bogged down in the intricate and lengthy task of creating an AI voice from the ground up? Users can easily input text and have a voice generated in just minutes! These are perfect for content creators, marketers, and businesses looking for voices for videos, podcasts, virtual assistants, or presentations.
A number of AI voice generators provide a variety of customizable voice options across multiple languages and accents. These tools find their place in everyday applications such as virtual assistants, e-learning platforms, audiobooks, and advertising, offering a swift and budget-friendly way to incorporate voice into projects without the need of advanced technical skills or expensive voice actors.
Individuals opt for a free AI voice generator as they provide a quicker, more convenient method to produce high-quality voices without the intensive resource requirements of developing models from the ground up.
Murf AI is a leading voice generator platform that offers a wide range of customizable voice options. This makes it ideal for creating high-quality voiceovers and audio content in minutes.
Here’s how to create artificial voices using Murf:
Visit the Murf AI website and create an account. You can sign up with an email address or click on Sign up with Google, Microsoft, and Slack for easy access.
After logging in, click on Create Project. Give a Project Title and you can also create a folder in which you can have multiple projects.
Enter the text you want to convert into speech. Murf allows you to paste or upload written content directly into the text editor. You can divide the text as per line or paragraph or edit the entire text in a single block.

Murf offers 200+ voice options across 20+ multiple languages and accents like English, French, and Spanish. You can browse through available voices and listen to samples to find the one that best suits your project. Options range from friendly, conversational, and cheerful voices to storytelling, furious, and terrified tones.
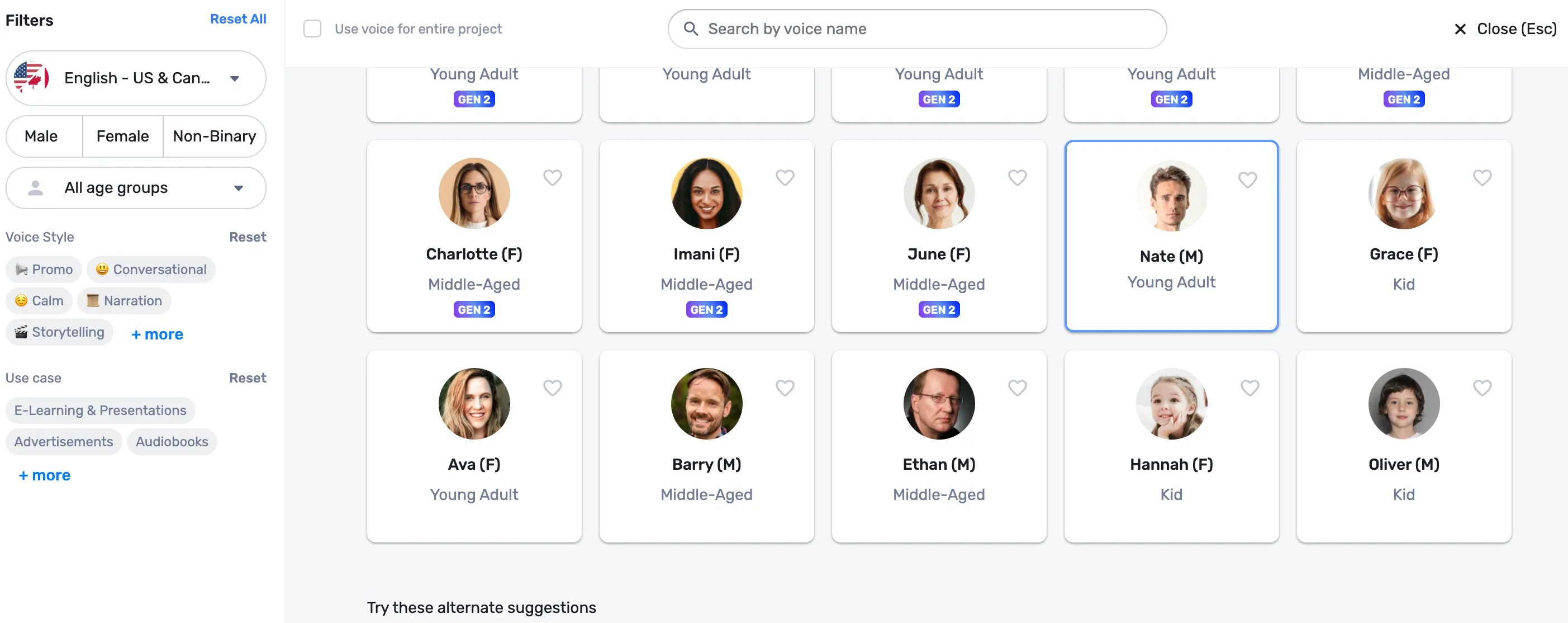
Once you’ve chosen a voice, you can customize it by adjusting speed, pitch, emphasis, and pause settings. The "Say it My Way" feature allows you to record your own voice and direct the model to capture the intonation, tempo, and pitch of your produced speech.

After customizing the voice settings, you can preview the output to ensure it sounds exactly as you want. You can also make adjustments to the written text or voice settings as necessary.
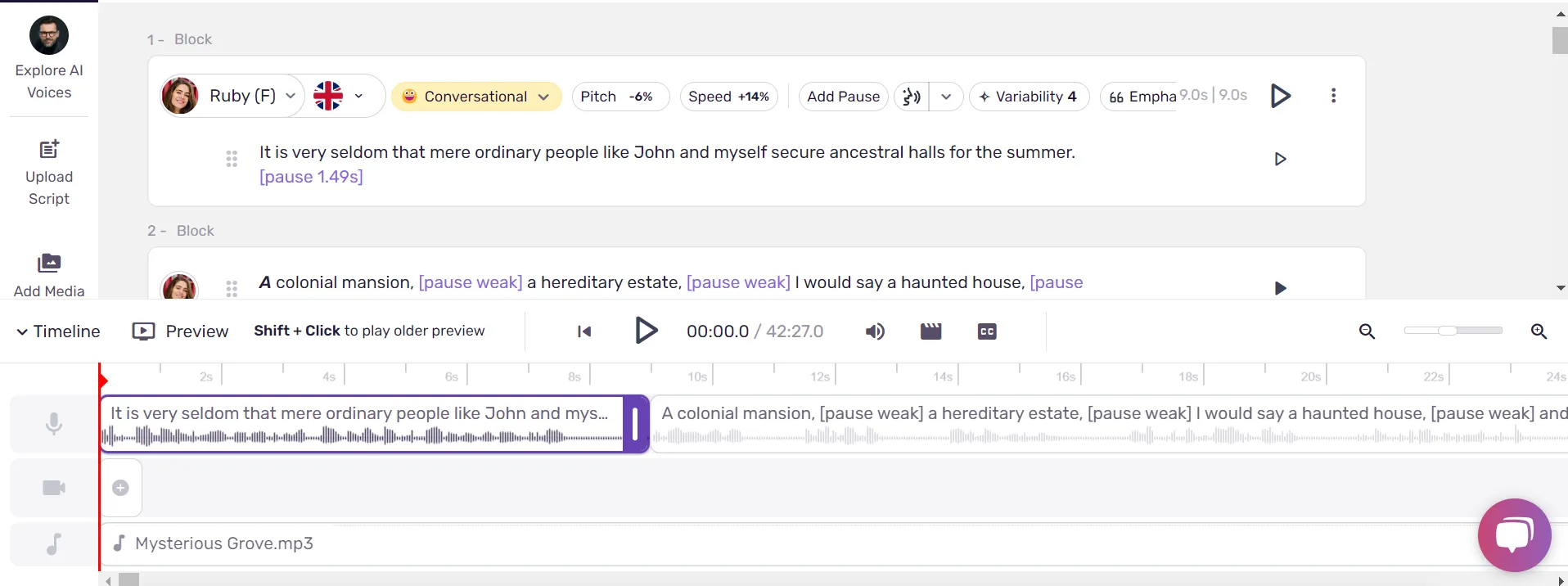
For example, suppose certain words need more emphasis or the pronunciation of a specific term needs adjustment. In that case, the word-level control feature allows you to tweak emphasis, pitch, or even the timing of individual words.
Once satisfied with the final product, you can generate AI voices. Murf provides an option to download the audio files in various formats (MP3, WAV), making it ready for use in your projects.
Building an AI voice from scratch is the more technical approach for total control and customization of the output. This approach teaches AI models to synthesize human-like speech depending on data sources.
Although this approach requires more time and resources, it has the advantage of producing a highly personalized synthetic voice with exact control over its tone, style, and other subtleties.
Building an AI voice from scratch requires many stages, from data collection to model deployment.
Getting high-quality speech data entails compiling voice samples as the basis for training the AI model. A strong dataset requires a lot of audio data with varied speech patterns, accents, and intonation. Once the data is acquired, it must be cleaned and labeled appropriately.
Next, we select a speech synthesis model as the AI foundation for voice production. To operate with PyTorch or TensorFlow machine learning models, you must create the required development environment.
In this environment, you will build and train the model, requiring a high-performance configuration to analyze vast volumes of data.
The next step is to train the AI model with the gathered data. Training provides the model with text and voice data, allowing it to learn how to translate text into naturally occurring speech.
Training can take a significant period, depending on the dataset's size and the model's complexity. The model keeps improving at predicting how words should sound, their pronunciation, and the suitable emotional tone for various settings.
After the first training, the model is tweaked to improve the speech quality produced. In addition to correcting any pronunciation errors, developers might adjust the tempo, pitch, and voice output clarity.
Lastly, the AI voice is tested and implemented. During this step, developers run the model through a set of test cases to ensure that the synthetic voice faithfully reproduces several kinds of input text naturally and consistently.
Although building AI voices from scratch provides unmatched customization and control, there are also significant ethical questions and issues involved.
Creating natural-sounding AI voices from scratch can introduce the following challenges:
One of the toughest obstacles in producing AI voices is obtaining high-quality speech data. The dataset must be varied and include a broad spectrum of speech patterns, emotions, and pronunciations.
Insufficient or low-quality data might result in poor voice output with pronunciation, intonation, and general clarity issues.
Teaching a machine-learning model to produce human-like speech requires significant computational capability. The heavy processing required calls for either cloud-based infrastructure or high-performance servers.
AI synthetic voices from scratch require an advanced understanding of speech synthesis technologies, Natural Language Processing (NLP), and machine learning. Developers must know how to gather and prepare data, train models, and adjust settings.
AI voices also have the following ethical challenges to consider:
Should the AI speech model's training data include prejudices such as gender, ethnic, or cultural ones these will show in the voice output.
For instance, an AI voice may sound more natural when using a standard American accent but struggle with non-native accents or minority dialects, leading to mispronunciations or inauthentic speech patterns. This leads to an uneven user experience, where the AI might appear more accurate or expressive for some groups while sidelining others, which could reinforce stereotypes or overlook diverse voices.
Impersonation and misleading behavior pose major risks, as realistic AI voices have the potential to generate deepfake audio files or replicate real people without authorization. Fraudulent activities, such as posing prominent personalities, celebrities, or even common people, can employ this technology to fool or control viewers.
AI generated voices are a great choice for individuals who need quick, dependable, and reasonably priced answers as they offer customization options and produce professional results in minutes.
Building AI-generated voices from scratch gives developers total control and customization, and it requires excellent data, computational tools, and machine learning knowledge.
Choosing between using an AI voice generator or building a voice from scratch depends on your goals, time, and resources. For most users, leveraging a tool like Murf AI will be the best ai voice generator for it's practical and efficient route.
Ready to experience the power of AI voices? Try Murf AI today and transform your text into lifelike speech effortlessly.
Sign up below and see how Murf can elevate your projects with state-of-the-art voice technology!

.svg)
AI voice generators are simple tools that allow users to generate voices quickly, requiring no technical expertise. In contrast, creating an AI voice from scratch is a complex process that requires data collection, machine learning knowledge, and high-performance computational resources for total control over voice output.
AI voice generators use text to speech technology to convert written text into spoken words. These tools analyze the text input and create a human-like voice output by adjusting pitch, speed, and tone.
Building an AI voice from scratch is a time-consuming process. It involves collecting voice data, training the model, and fine-tuning the output, which can take weeks or even months, depending on the complexity and the amount of data.

![Murf Ai vs Luvvoice: Tried Both & Here's the Winner [2026]](https://cdn.prod.website-files.com/675151245f2993547dbd5046/697b409c8a14e7084646faec_69203f6139e64d8f36be229d_Murf%2520Ai%2520vs%2520Luvvoice%2520Tried%2520Both%2520%2526%2520Here%2527s%2520the%2520Winner%2520%255B2025%255D.webp)
![Murf AI vs Speechma: Tried Both & Here's the Winner [2026]](https://cdn.prod.website-files.com/675151245f2993547dbd5046/697b40a45c450448e7d67fb9_69203e67d0323e7945075e13_Murf%2520AI%2520vs%2520Speechma%2520Tried%2520Both%2520%2526%2520Here%2527s%2520the%2520Winner%2520%255B2025%255D.webp)
Keeping your data safe


Learn how we help enterprises expand globally at scale



