Our Flagship Model
Murf Speech Gen 2 is our most advanced, realistic, and customizable speech synthesis model. It merges human-like realism with advanced speech customization features, enabling granular control over pitch, speaking rate and emphasis.
Enhanced Fidelity and Precision in AI-Generated Voice
Murf Speech Gen 2, designed with Murf’s proprietary, state-of-the-art, generative neural architecture, produces voices that are indistinguishable from human speech. Trained on over 70,000 hours of ethically sourced speech data spanning diverse demographics and emotional ranges, the model captures natural inflections and rhythm with unprecedented accuracy.
Murf Speech Gen 2 operates natively at 44.1kHz sampling rate, allowing it to capture the entire human audible range more precisely. This high-fidelity output preserves complex phonetic interactions, such as sibilance combinations in ‘s’ and ‘f’ sounds, delivering consistently natural voice quality.
Expressive Speaking Styles
Styles is a core model capability that enables dynamic modification of voice characteristics during speech synthesis. Our models are trained to recognize and apply specific speaking patterns, allowing them to transform a base voice’s tone, emotional inflection, and delivery characteristics to match predefined speaking contexts while maintaining natural speech quality.
The following demos, created using Murf Speech Gen 2, showcase voiceovers that exemplify these capabilities.
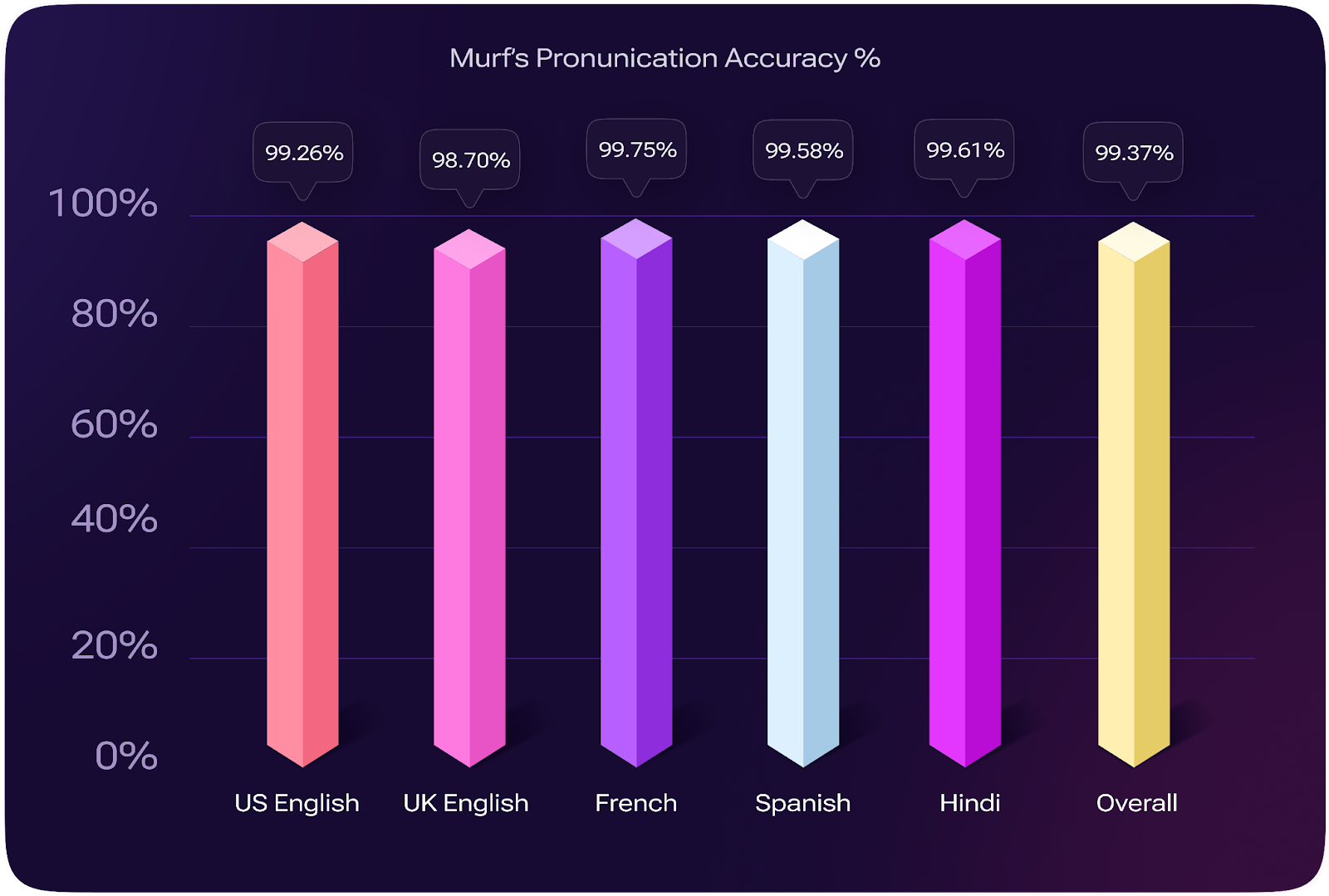
Unparalleled Pronunciation Accuracy
Our deep linguistic modeling layer enables Gen 2 to capture accent-specific phonological patterns across multiple languages with high precision. The model’s advanced phoneme-level understanding ensures accurate reproduction of language-specific features, including stress patterns, tonal variations, and dialectal nuances.
An independent blind test conducted across five languages confirmed industry-leading performance, achieving 99.37% pronunciation accuracy. We evaluated pronunciation accuracy using a test set of 300,000 news sentences. To ensure broad linguistic coverage, we selected 2,610 commonly used words from the high-frequency band (e.g., “find,” “about”) and 2,100 moderately common words from the medium-frequency band (e.g., “planner,” “discuss”). Each word’s pronunciation was evaluated by two independent native speakers.
MultiNative Speech Generation
Murf Speech Gen2 supports MultiNative technology, enabling text-to-speech synthesis that sounds authentically native across multiple languages. Through its neural network architecture, it separately models language-specific features (prosody, phonemes, accents) while maintaining consistent voice identity. This allows the same voice to speak multiple languages while preserving natural pronunciation patterns specific to each language, effectively eliminating the “foreign accent” effect common in conventional multilingual TTS systems.
Advanced Customization Through Variation
Variation is our solution to the dynamic nature of human speech. With this, developers can choose on a scale of 1 to 5 for creating voiceovers that suit their use case. To illustrate what ‘Variation’ can achieve, in the video below, we take inspiration from a popular episode of ‘The Graham Norton Show’ linked here, an exceptional example of voice acting.
Customize With Say It My Way
The Voice Changer API enables granular control over voice synthesis by using reference audio as input. When you provide a recorded speech sample, the model analyzes its acoustic patterns including intonation, pacing, and pitch variations. These extracted parameters are then applied to the target voice during generation, replicating the temporal characteristics, word emphasis patterns, and pause structures of the reference audio, ensuring the output mirrors your intended delivery style.
Our Commitment Towards Ethical AI
At Murf, we recognize the power of AI in transforming voiceover workflows but are equally aware of the ethical responsibilities it brings. As pioneers in AI voice technology, we are committed to upholding the highest standards of ethics to ensure our innovations benefit everyone involved – creatively, responsibly, and fairly. We ensure our voice technology reflects the diverse world we live in. For instance, our voices span various age-groups, accents, genders and cultural backgrounds, making our technology accessible and representative of all users. We use ethically sourced datasets which have been created with the consent and collaboration of voice actors from around the world. Transparency is key; we openly share how our AI voices are created and used, ensuring users understand the process and trust its integrity. Additionally, we rigorously protect user data, upholding strict privacy standards to secure the personal information entrusted to us. By prioritizing these ethical principles, Murf not only advances technology but does so with a conscience, enhancing human creativity without compromising values. Read more about our ethical practices here.