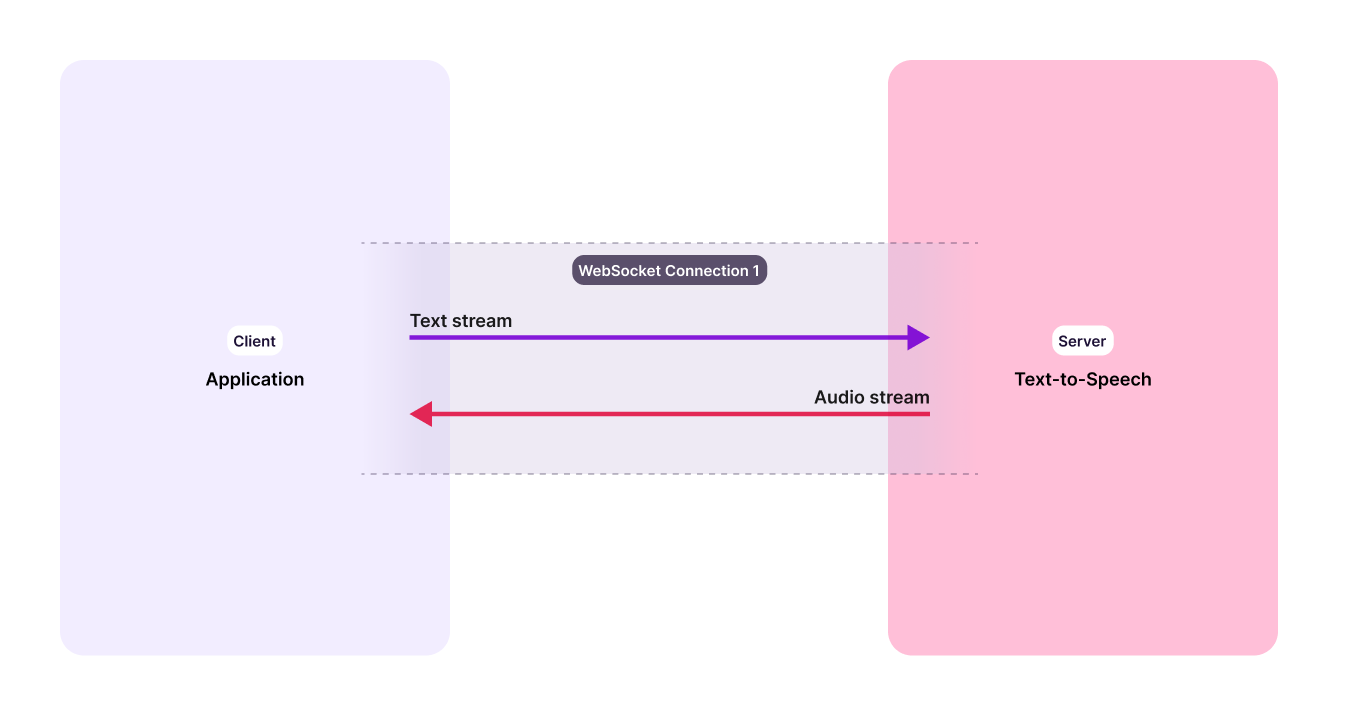
WebSockets
Murf TTS API supports WebSocket streaming, enabling low-latency, bidirectional communication over a persistent connection. It’s designed for building responsive voice experiences like interactive voice agents, live conversations, and other real-time applications.
New: Pass model = falcon-2 to use our Falcon 2 model in text-to-speech
streaming endpoints, designed for ultra-low latency (~100 ms).
With a single WebSocket connection, you can stream text input and receive synthesized audio continuously, without the overhead of repeated HTTP requests. This makes it ideal for use cases where your application sends or receives text in chunks and needs real-time audio to deliver a smooth, conversational experience.
Quickstart
This guide walks you through setting up and making your first WebSocket streaming request.
Getting Started
Generate an API key here. Store the key in a secure location, as you’ll need it to authenticate your requests. You can optionally save the key as an environment variable in your terminal.
Install required packages
This guide uses the websockets and pyaudio Python packages. The websockets package is essential for the core functionality.
Note:
pyaudiois used in this quickstart guide to demonstrate playing the audio received from the WebSocket. However, it is not required to use Murf WebSockets if you have a different method for handling or playing the audio stream.
pyaudio depends on PortAudio, you may need to install it first.
Installing PortAudio (for PyAudio)
PyAudio depends on PortAudio, a cross-platform audio I/O library. You may need to install PortAudio separately if it’s not already on your system.
macOS
Linux (Debian/Ubuntu)
Windows
Once you have installed PortAudio, you can install the required Python packages using the following command:
Falcon 2 Supported Voices
English - US & Canada
English - UK
English - India
English - Australia
French - France
French - Canada
German - Germany
Spanish - Mexico
Spanish - Spain
Italian - Italy
Portuguese - Brazil
Mandarin - China
Dutch - Netherlands
Hindi - India
Korean - Korea
Tamil - India
Polish - Poland
Bangla - India
Japanese - Japan
Gujarati - India
Kannada - India
Malayalam - India
Marathi - India
Punjabi - India
Telugu - India
Available Regions
Use the region closest to your users for the lowest latency.
The Global Router automatically picks the nearest region automatically.The concurrency limit is 15 for the US-East region and 2 for all other regions. To get higher concurrency, use the US-East endpoint directly or contact us to increase limits for regional endpoints.
Best Practices
Following are some best practices for using the WebSocket streaming API:
- Once connected, the session remains active as long as it is in use and will automatically close after 3 minutes of inactivity.
- You can maintain up to 10X your streaming concurrency limit in WebSocket connections, as per your plan’s rate limits.
- For the lowest latency, prefer Falcon 2 voices by setting model =
falcon-2.
Next Steps
Use a unique identifier to track a specific TTS request, ensuring continuity in the conversation.
Fine-tune text buffering to balance audio quality and Time to First Byte (TTFB).
FAQs
How is WebSocket streaming different from HTTP streaming in the Murf TTS API?
WebSocket allows you to stream input text and receive audio over the same persistent connection, making it truly bidirectional. In contrast, HTTP streaming is one-way, you send the full text once and receive audio while it is being generated. WebSocket is better for real-time, interactive use cases where text arrives in parts.
What format is the audio received over WebSocket?
The audio is streamed as a sequence of base64-encoded strings, with each message containing a chunk of the overall audio
After how long will the WebSocket connection close due to inactivity?
The WebSocket connection will automatically close after 3 minutes of inactivity.
What features can I use with the WebSocket Streaming API?
You can control style, speed, pitch and pauses.
How do I enable Falcon 2 over WebSockets, and who should use it?
Add model = falcon-2 to your WebSocket connection query (or request
parameters). Falcon 2 is optimized for ultra-low latency (~100 ms) and is
ideal for interactive agents, live support, gaming, tutoring, and other
real-time experiences where fast turn-taking matters.